Синтаксический анализ представляет собой разбиение единого целого на компоненты, обычно целого предложения на отдельные слова. В качестве первого шага по преобразованию вашего сценария в HTML-документ PHP делает синтаксический анализ. После этого наступает момент выборки или проверки данных из строки. Это может быть достаточно просто, как при обработке списка слов, разделенных пробелами, или достаточно сложно, когда речь идет о строке, с помощью которой браузер идентифицирует себя на Web-сервере. Одним из решений может быть пометка строки с разбиением ее на части, но можно прибегнуть и к помощи регулярных выражений. В этой главе мы рассмотрим возможности PHP по синтаксическому анализу и оценке строк.
22.1. Пометка строк
Для пометки строк PHP применяет простую модель, а именно: определенные символы считаются разделителями, а символические строки, расположенные между разделителями, - маркерами. Набор разделителей можно менять по мере выборки маркеров из строки, что просто незаменимо при обработке "неправильных" строк, т.е. таких, которые нельзя отнести к строкам, разделенным запятыми.
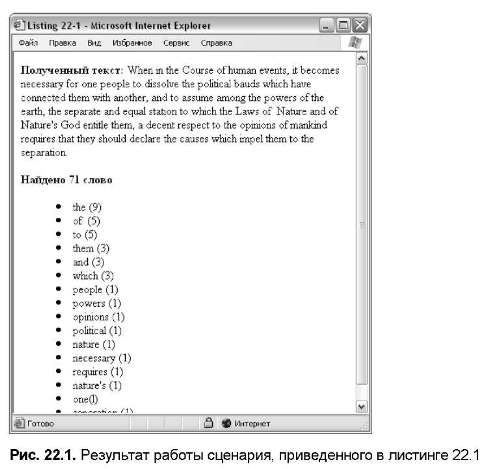
В листинге 22.1 принимается предложение и разбивается с помощью функции strtok (см. главу 12, "Кодирование и декодирование") на слова. Если речь идет о сценарии, слово завершается пробелом, знаками пунктуации или символом "конец строки". Одинарные или двойные кавычки считаются частью слова. Результат работы сценария показан на рис. 22.1.
Листинг 22.1. Пометка строк
<?php /*
** Если предложение завершено, проанализировать его */
if(isset($_REQUEST['sentence'])) {
$total=0;
print("<b>Полученный текст:</b>"); print("{$_REQUEST['sentence']}<br>n<br>n"); //задать символы, разделяющие маркеры $separators = " ,!.?",-//получить маркеры
for($token = strtok($_REQUEST['sentence'], $separators); $token !== FALSE; $token = strtok($separators))
{
// Пропустить пустые маркеры
if($token != "")
{
// сосчитать слова
if(!isset($word_count[strtolower($token)]))
{
$word_count[strtolower($token)]=1;
}
else
{
$word_count[strtolower($token)]++;
}
$total++;
}
}
//сначала отсортировать по словам
ksort($word_count);
//затем отсортировать по частоте
arsort($word_count);
print("<b>Найдено $total слов </b>n"); print("<ul>n");
foreach($word_count as $key=>$value)
{
print("<li>$key ($value)</li>n");
}
print("</ul>n");
}
print("<form action="{$_SERVER['PHP_SELF']}" " .
"method="post">n");
print("<input name="sentence" size="40">n"); print("<input type="submit" value="Parse">n"); print("</form>n");
?>
Обратите внимание на использование в этом примере цикла for. Вместо наращивания счетчика он принимает поочередно маркеры. Когда функция strtok достигает конца вводимой информации, она возвращает значение FALSE. Первым намерением может быть проверить значение FALSE в цикле for с помощью оператора !=. Напомним, что пустая строка считается эквивалентной значению FALSE. Если два разделителя следуют друг за другом, то, как можно ожидать, функция strtok возвратит пустую строку. Так как останавливать разбивку на маркеры после каждого повторяющегося оператора в наши планы не входит, выполним проверку значения FALSE с помощью оператора !==.
Использование функции strtok целесообразно только в самых простых и структурированных случаях. Примером такой ситуации является чтение текстового файла, разделенного символами табуляции. Алгоритм может заключаться в следующем: выборка маркеров из строки с использованием в качестве пробела символа табуляции, а затем - выборка следующей строки из файла.
PHP. Синтаксический анализ и обработка строк
23-05-2015
| << Предыдущая статья | Следующая статья >> |
| PHP. Сортировка, поиск и случайные числа. Часть Шестая. | PHP. Синтаксический анализ и обработка строк. Часть Вторая. |