В листинге 22.3 представлен сценарий, предназначенный для создания набора переменных, которые помогут в маскировании Web-узла для определенного браузера. В целях иллюстрации мы настроим связь в соответствии с используемым браузером. Если пользователь посещает эту страницу с помощью браузера Netscape Navigator, мы предоставим ссылку на страницу загрузки для браузера Internet Explorer. В противном случае мы предоставим ссылку на страницу загрузки для браузера Netscape. Это один из примеров настройки содержимого. Аналогичным способом можно воспользоваться, чтобы принять решение о том, использовать ли дополнительные возможности.
Листинг 22.3. Оценка пользовательского агента
// оценить пользовательский агент как
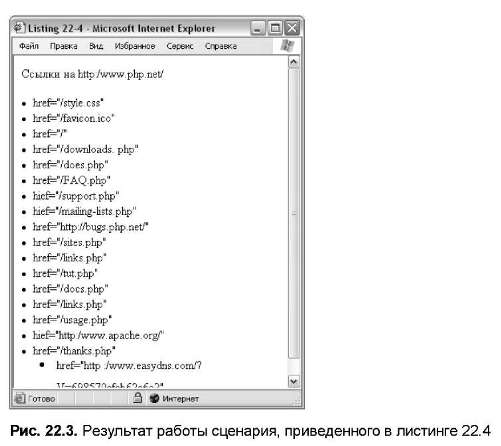
//Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; Q312461) ereg("*([[:alpha:]]+)/([[:digit:].]+)( .*)Для преобразования текста с целью его использования в новом контексте я часто используют функцию ereg_replace. Для объединения множества пробелов в один пробел можно использовать ereg_replace. Применение этого решения продемонстрировано в сценарии, приведенном в листинге 22.5, а результат работы этого сценария - на рис. 22.4.
Листинг 22.5. Замена нескольких пробелов
<?php
/*
** отобразить замещенный текст
*/
if(isset($_REQUEST['text']))
{
print("<b>Не отфильтровано</b><br>n" . "<pre>{$_REQUEST['text']}</pre>" . "<br>n");
$_REQUEST['text'] = ereg_replace("[[:space:]]+",
" ", $_REQUEST['text']); print("<b>Отфильтровано</b><br>n" .
"<pre>{$_REQUEST['text']}</pre>" .
"<br>n");
}
else
{
$_REQUEST['text'] = "";
}
// начальная форма
print("<form action="{$_SERVER['PHP_SELF']}">n" .
"<textarea name="text" cols="40" rows="10">" . "{$_REQUEST['text']}</textarea><br>n" . "<input type="submit">n" . "</form>n");
?>quot;,
$_SERVER['HTTP_USER_AGENT'], $match); $browserName = $match[1]; $browserVersion = $match[2]; $browserDescription = $match[3]; //поиск подтверждений в том, что это MSIE if(eregi("msie", $browserDescription))
{
//поиск чего-то наподобие
//(compatible; MSIE 6.0; Windows NT 5.1; Q312461) eregi("MSIE ([[:digit:].]+);", $browserDescription, $match); $browserName = "MSIE"; $browserVersion = $match[1];
}
print("E>bi используете $browserName " .
"версии $browserVersion!
n" .
"Вам следует воспользоваться "); if(eregi("mozilla", $browserName))
{
print(""http://www.microsoft.com/ie/download/default.asp">"); print("Internet Explorer"); print(" ");
}
else
{
print(""http://www.netscape.com/computing/download/".
"index.html" ."">"); print("Navigator");
print(" ");
}
print("для сравнения.
n");
?>
В этом сценарии основная функция ereg в операторе if не используется. Здесь предполагается, что браузер идентифицирует себя минимум именем, косой чертой и версией. Массив match принимает набор с частями оцениваемой строки, которые соответствуют частям регулярного выражения. Есть три субвыражения для имени, версии и любого дополнительного выражения. Большинство браузеров, включая Navigator и Internet Explorer, используют такую форму, так как Internet Explorer всегда сообщает о том, что он является браузером Mozilla (Netscape), и для того чтобы распознать его как такового, необходимо вызвать функцию eregi.
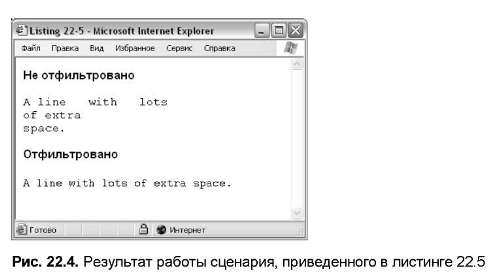
Остается невыясненным, почему в этом алгоритме игнорируется нулевой элемент. Это происходит потому, что нулевой элемент содержит подстроку, соответствующую всему регулярному выражению. Но в данном случае это нас не должно интересовать. Обычно нулевой элемент используется при поиске определенной строки в большом контексте, например, при проверке Web-страницы на наличие в ней URL. В листинге 22.4 выбирается начальная страница PHP и приводится перечень всех ссылок, имеющихся на ней, а на рис. 22.3 показан результирующий вывод.
Листинг 22.4. Сканирование текста на наличие URL
//задать искомый URL
$URL = "http://www.php.net/";
// открыть файл
$page = fopen($URL, "r");
print("Ссылка на $URL
n");
print("
-
n");
- {$match[0]} n");
while(!feof($page))
{
//получить строку
$line = fgets($page, 1024);
//просмотреть, где по-прежнему имеются URL while(eregi("href="[*"]*"", $line, $match))
{
// распечатать URL
print("
// удалить все URL из строки
$replace = ereg_replace("?", "?", $match[0]); $line = ereg_replace($replace, "", $line);
}
}
print("
n"); fclose($page);
?>
Главный цикл этого сценария принимает текстовые строки из файлового потока и просматривает их на наличие свойства href. Если таковое найдено, оно будет размещено в нулевом элементе массива match. Сценарий распечатает его, а затем удалит его из строки с помощью функции ereg_replace. Эта функция замещает текст, соответствующий регулярному выражению, строкой. В таком случае сценарий замещает свойство href пустой строкой. Необходимость поиска ссылки с последующим его удалением может заключаться в возможности присутствия сразу двух ссылок в строке HTML-кода. Функция eregi будет соответствовать только первой подстроке. Решение заключается в поиске и удалении всех ссылок до тех пор, пока не останется ни одной.
Заметим, что при удалении ссылки готовится переменная replace. Некоторые ссылки могут иметь знак вопроса, который является допустимым символом URL, предназначенным для отделения имен файлов от переменных. Поскольку этот символ имеет в регулярных выражениях специальное значение, этот сценарий размещает перед ним обратную косую черту, чтобы дать понять PHP, что он будет рассматриваться как литерал.
Для преобразования текста с целью его использования в новом контексте я часто используют функцию ereg_replace. Для объединения множества пробелов в один пробел можно использовать ereg_replace. Применение этого решения продемонстрировано в сценарии, приведенном в листинге 22.5, а результат работы этого сценария - на рис. 22.4.
Листинг 22.5. Замена нескольких пробелов
<?php
/*
** отобразить замещенный текст
*/
if(isset($_REQUEST['text']))
{
print("<b>Не отфильтровано</b><br>n" . "<pre>{$_REQUEST['text']}</pre>" . "<br>n");
$_REQUEST['text'] = ereg_replace("[[:space:]]+",
" ", $_REQUEST['text']); print("<b>Отфильтровано</b><br>n" .
"<pre>{$_REQUEST['text']}</pre>" .
"<br>n");
}
else
{
$_REQUEST['text'] = "";
}
// начальная форма
print("<form action="{$_SERVER['PHP_SELF']}">n" .
"<textarea name="text" cols="40" rows="10">" . "{$_REQUEST['text']}</textarea><br>n" . "<input type="submit">n" . "</form>n");
?>